We've been fairly busy at Eleuther for the past year-and-a-half, here's the full story.
July 2021 – December 2021: An Interlude
Language Modeling
When we last left off, GPT-NeoX was a pipe dream. A global GPU shortage had halted our progress in its tracks.

Luckily, it was just about this time that the cluster that CoreWeave was building for this project was finally having the finishing touches placed on it. We started taking it for a test drive, but the initial results were subpar to say the least. InfiniBand was a very different interconnect technology than we had previously worked with, and it took a full two weeks of trial, error, Dockerfiles and microbenchmarking to form our environment into something we were happy with.

And so the time came. Everything was finally in place. We completed our final readiness checks, and without any dissenting responses at the time, we pressed go.
One problem: In our haste to start the run, we had forgotten to consider checkpoint storage. Unlike most training runs, it was our desire to archive all checkpoints for later analysis, and the mount that we configured to store our checkpoints wouldn’t be large enough for all of them. After much discussion, it was determined that the safest course of action would be to leave the existing run alone and occasionally empty out hot storage to cold storage manually. This would have been fine—if we would always remember to transfer checkpoints before hot storage ran out.
Of course, we forgot. More than once. The run would crash, and we would have to fix the collateral damage.
We were curious how closely bored nerds with nothing better to do were following our every move—so we decided to leave the Weights & Biases training run unannounced and public before waiting to see who noticed. As far as we can tell, the first person to notice was a lone anonymous user on 4chan, who was promptly ignored by the community until the run was rediscovered by the 4chan community over a week later on November 18, 2021. Shortly after, people started asking about the model.
Multimodal Modeling
Our July 2021 retrospective, a short section was dedicated to #the-faraday-cage and its resident art gen service BATBot. We had no way of knowing that that service was about to get a huge shot in the arm.
On July 19th, just a few weeks after our retrospective was published OpenAI released their ImageNet diffusion models. According to their model card OpenAI was only willing to release the models because they couldn’t generate anything outside the ImageNet classes. How they conducted their assessment isn’t publicly known, but they missed something because a mere six days later on July 25th RiversHaveWings developed a CLIP Guided Diffusion algorithm using the new models. The hacker known as EleutherAI had struck again.
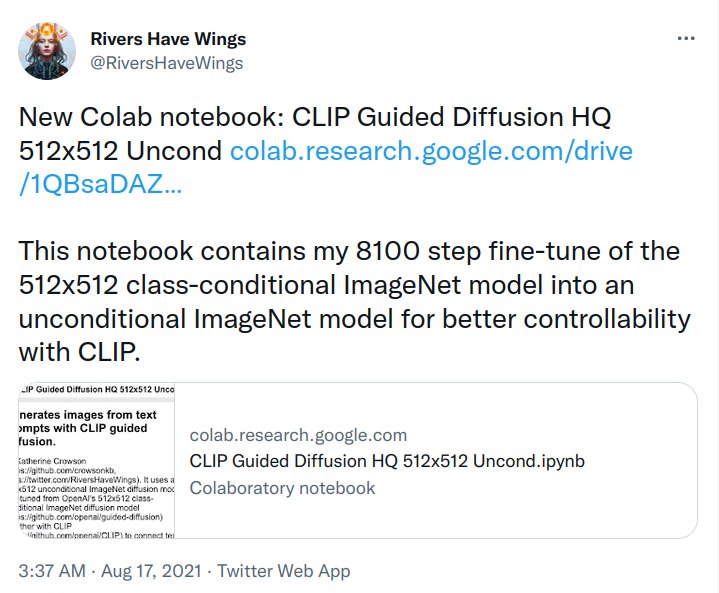

CLIP-Guided Diffusion, like VQGAN-CLIP before it, allowed us to do text-to-image modeling without spending millions of dollars pretraining models. Models like the original DALL-E are ludicrously expensive to train (even by large scale AI research standards) and would be largely inaccessible to artists and researchers even if they were publicly released. Our models were clearly worse, but they required tens of thousands to hundreds of thousands fewer GPU-hours to train and could be deployed in a Google Colab. Soon though, we’d ge to try our hand at training our own models.
January 2021 – March 2022: Something Pithy Goes Here
Our original plan was to release GPT-NeoX-20B at the end of the year, marking the one year anniversary of the Pile’s release. However our loss curves looked weird, and the model continued to improve faster than we anticipated. When we reached the end of the Pile (~300B tokens, the same size as the GPT-3 training corpus), we decided to start another epoch and see what happened.
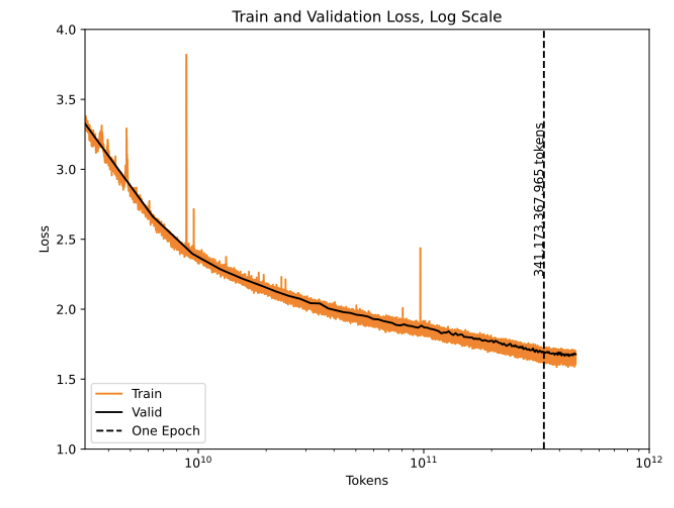
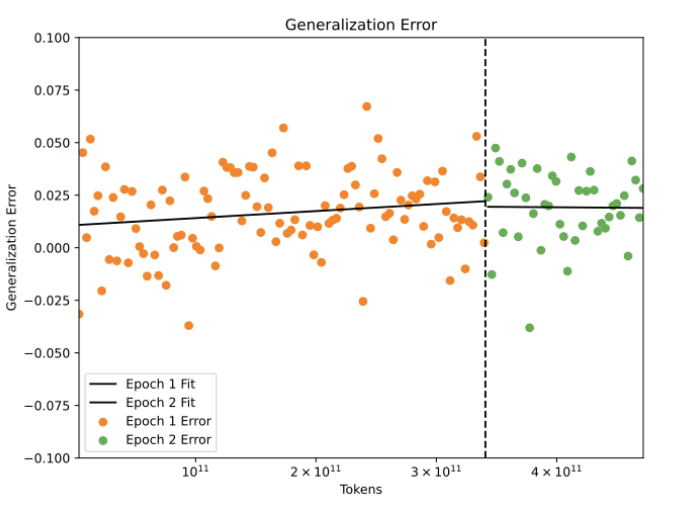
“What happened” was that the loss kept going down, benchmark performance kept increasing, and there was no sign of increased generalization error. We had no way of knowing it at the time, but what we were seeing was the first hint of “Chinchilla Scaling Laws” from DeepMind’s seminal paper a few months later. We decided to end training in late January after 400B tokens, which turned out to gave us the first chinchilla-optimal language model completely by happenstance.

We typically don’t provide timelines or roadmaps, but as an additional motivator we committed to a timeline for full release—in an announcement that mentioned @everyone and a blog post that was widely shared on the web. And so we were stuck with it. Whether we were ready or not, February 9, 2022 it was. Of course, our work was far from done: We had a model, but we had much to document. The next week was a mad dash of writing, benchmarking, and analysis.

But, as promised, we were able to complete a draft paper which we released along-side the full model weights. We have also promised to give access to the partially trained checkpoints to anyone who asks, but have received zero serious requests for the partially trained checkpoints so far.
We learned a lot from this experience, including just how hard language model evaluation is. Very minor tweaks in language model evaluation protocols that wouldn’t even be noticed by a human can wildly change performance. For example, MMLU benchmark features multiple choice questions with answers labeled “a” through “d.” The recommended way to evaluate models is to compare the log probabilities of the letter corresponding to the correct answer. However if you instead compare the actual answers performance shoots up: in our testing the difference is comparable to scaling from 6.7B parameters to 175B parameters.

Grading the model’s ability to produce “Branch of the thyrocervical trunk” rather than “C” results in much higher accuracy on average.
We also learned just how important it is to get the narrative right the first time. Our blog post originally claimed that GPT-NeoX-20B underperformed FairSeq Dense 13B (then the largest publicly available English LLM) on standard NLP benchmarks like Lambada and HellaSwag. This wasn’t in fact true, the issue was a bug we discovered in the shard merging code that hurt performance. While we eventually found ways around this bug, and all numbers in our paper were reported using the (better) unmerged model, we still get occasional questions from people who think that GPT-NeoX-20B’s performance on NLP tasks was disappointing.
Training our own Multi-Modal Models
While alstroemeria’s Promethean episode with CLIP guided diffusion ushered in a new era of high quality neural net art, it was far from perfect. Fortunately, text-to-image and diffusion research saw breakthrough after breakthrough, leading to less and less compute being needed to train or use the models. The early months of 2022 were a mad dash of new techniques and new combinations of old techniques, with one week seeing three new SOTA models each obviously better than the previous.
Writing about this now is a bit weird, as many of the major breakthroughs are far, far behind what models like StableDiffusion and Midjourney can do today. We’ve been thinking about releasing a deep dive on the history of text-to-image synthesis, but for now it is sufficient to say that Katherine and JD were very busy training models and reading new papers.
Alignment Education
This time period also saw a pronounced uptick in conversations about AI Safety, interpretability, and other related topics. A lot of productive discourse has come out of these discussions on a variety of AI Safety related topics, ranging from more prosaic alignment concerns like interpretability and mesa-optimization, to more abstract problems such as logical induction and infinite ethics. Some of this has indirectly made its way to venues like the alignment forum, and some of our members have managed to get prizes and honorable mentions for the ELK prize.

However, probably the most notable success of this period and the one before it would have to be the various reading groups. EAI has hosted a variety of reading groups either directly or tangentially related to alignment.
The most notable of these is the interpretability reading group, which has been not only scouting out cutting edge papers on neural network interpretability, but also finding authors and bringing them in to present their research. Other things include hosting a modified version of Richard Ngo’s alignment curriculum, to introduce some of our newer members to the field of alignment.
April 2022 – July 2022: EleutherAI’s “Identity crisis”
After GPT-NeoX-20B came out, EleutherAI entered a prolonged lull, to the point where we sometimes wondered if EleutherAI was over. There were a couple reasons for this, but the main one was an exodus of former leaders to their next employers and the remaining active members focusing primarily on work that was being organized elsewhere. This began a vicious cycle: people wanted to be where the activity was, leading them to go do work outside of EleutherAI, leading to less research activity in EleutherAI.
Conjecture
Connor wasn’t satisfied with sporadic and voluntary geese posting on Eleuther, so he finally set out to found an organization where he could legally force employees to plaster the walls with geese pictures (and to not share infohazards!).
As wonderful as the pirate life at EleutherAI had been, Connor and others unfortunately ran into many bottlenecks, in particular, that you can’t really get people to do boring things they don’t want to do if you don’t pay them.
Imagine herding cats, but the cats are the smartest people you’ve ever met and also have crippling ADHD. This is what EleutherAI is like. And what a great, lovely, hive of scum and memery it is! But ultimately to address some of the truly big, hard problems the future holds, a more structured organization was necessary. And hence, Conjecture was born!
Since Conjecture officially launched in March, things have proceeded at breakneck speed. Starting with three founders and 5 early employees in a cramped, musky WeWork, Conjecture has now grown to 18 people full time, the first cohort of the alignment research incubator Refine, the first cohort of SERI MATS in the UK across the street, and many more new qualia of waterfowl and non-waterfowl nature. Conjecture works on making Connor’s dream of making anime disappear come true applied alignment research and diversifying bets in the alignment field.
Conjecture’s work so far has focused on mechanistic interpretability, including work on polysemanticity in neural networks, researching new frames to think about LLMs on researching GPT-like LLMs and their properties, on building a tech stack to train and deploy new and existing models very quickly, epistemology, and on increasing coordination in the field to tackle the alignment problem head on. But above all, Conjecture is a focused, sincere shot at doing whatever it takes to solve alignment, a merry band of buccaneers that don't know how to save the world, but they sure as hell are going to try.
The pirates are industrializing!
CarperAI
Towards the end of 2021, Louis had concluded a research project on preference learning, and was beginning to see the limits of constraining himself to a single discord channel. He was beginning to notice a void in the open source space, there was no one attempting to directly tackle Instruct GPT like models akin to what OpenAI had produced months prior. In mid spring 2022 he set out to build CarperAI, to fill this niche.
CarperAI is focused on the democratization of RLHF and RLHF adjacent methods. They want every lab, both academia and industry, to be able to utilize RLHF in their research. In the past 8 months, CarperAI has grown to 13 full-time and over 40 volunteers, and released two major libraries: trlX and OpenELM.
Other Organizations
The BigScience Research Workshop: Stella and Jon got heavily involved in the BigScience Research Workshop in mid 2022. Beyond the research they did in BigScience, this had another major impact: meeting new collaborators (incl. Hailey Schoelkopf, Lintang Surawika, and Colin Raffel) that would become prominent contributors to EleutherAI projects in the future.
Stability AI: Most people who had experience working on text-to-image modeling were scooped up by Stability. While Stability supports them releasing their work open source, and some like Katherine continued to collaborate with people in EleutherAI, this work gradually shifted text-to-image research out of our server.
OpenAI: Ben Wang joined OpenAI to work on language model research. Leo Gao joined OpenAI to continue his work on his alignment research agenda. Leo continues to contribute to alignment discussions in EleutherAI.
Closing the Book on VQGAN-CLIP
While members of EleutherAI did research on a variety of topics during this period, there was very little that was being lead by EleutherAI as an organization. The major exception is that we finally wrote a paper on VQGAN-CLIP, the original text-to-image synthesis and editing model we developed back in spring 2021. It was a tad late (by which we mean it has been used a billion times before we wrote a paper about it) but it would be eventually published at ECCV 2022.
August 2022 and Beyond: Reorganization and Revitalization
Stella eventually reached the same conclusion that Connor did: EleutherAI was too chaotic and unstructured, and it’s extremely difficult to retain talent when you’re effectively teaching people skills that pay hundreds of thousands of dollars per year and then asking them to do the work for free. She had also gotten offers from some LLM companies, but didn’t think it would be right for her to stop working on open source AI. Instead, she spent the summer quietly working on a plan to reorganize and revitalize EleutherAI as a non-profit research institute.
Stella hypothesized that the core problem was getting people back to work, or more precisely, getting people to start doing work organized in the discord server. As we would later detail in a NeurIPS Workshop paper on large ML collaborations, doing research in the public view has always been a crucial component of EleutherAI’s impact and marketing strategy. The reason to come to our discord server to talk about AI research was because it was a place where people could get unprecedented access to people doing cutting edge AI research, and AI researchers could interact with one another in an unstructured fashion. Even for people who didn’t participate in our research projects, being around the people who did was one of the major draws.
To jumpstart the process, she started the #interpretability-over-time channel for her Pythia project, talked Aran Komatsuzaki and Katherine Crowson into organizing on-going research projects in the discord server (#improved-t5 and #k-diffusion respective), and worked to help current and previous core contributors secure funding to do EleutherAI as a part-time job.
A great deal of this revitalizing activity was facilitated by StabiltyAI, which stepped in to lend critical support so that EleutherAI could continue to pursue it’s research objectives and revitalize itself. Slowly but surely, the plan worked. As activity stepped up in EleutherAI (and as we began to better advise our work, via our new Twitter and the #announcements channel)
Shifting Research Priorities
The past six months had shown that the world was rather fundamentally different from the way it was when we got started. When we released GPT-NeoX-20B in February 2022, it was the largest freely and publicly available language model in the world. By the end of 2022, GPT-NeoX-20B was in a three-way tie for sixth and the largest matched the size of the original GPT-3 model.
EleutherAI got into large scale AI training because we felt that researchers needed to have hands-on access to technologies like GPT-3. When we got started that meant that we had to train and release the models for people to use. Now, we are free to pursue the research we wanted to use these models to do in the first place, to study topics like interpretability, alignment, and learning dynamics. This was always the plan, but when we reconvened towards the end of 2022 it felt for the first time like the torch had been passed and that the world wasn’t going to be reliant on us training models to get access to them. We were now free to study whatever we wanted… the only question was, what is that?

NLP Research
While we continued to do some NLP research, the contents and context of that research has changed substantially, focusing on building better scientific understandings of the functionality of language models and making non-SOTA models more useful and accessible to small scale practitioners. These projects include:
- The “Improved T5” project, which investigates scaling laws for encoder-decoder models, and how many of the new developments for decoder-only models can be adapted to encoder-decoder ones.
- The PolyGlot Project, which trains small LLMs in a variety of languages. Currently, almost all billion+ parameter LMs are trained in one of three languages: English, Chinese, and “massively multilingual.” The Polyglot team trained and released Polyglot-Ko, a series of Korean language models that include the most performant FOSS Korean language model in the world and is now investigating “localized” multilingual models focused on South and South East Asian languages, Romance Languages, and Nordic languages.
- Jason Phang is working on hypermodels for LLMs for back-propagation-free model adaptation.
Interpretability Research
With our new-found invigoration, much of our energy has gone to interpretability work. Our biggest release along these lines so far has been Pythia, a suite of language models ranging from 19M to 13B parameters that was designed to study how models develop over the course of training and how those patterns change as models are scaled will yield important insights. This has been a pet project of Stella’s for close to a year now, and thanks to the hard work of Hailey Schoelkopf and Shivanshu Purohit it has finally come to fruition.
We released the models to the public on December 16th and the positive response from the community has been immediate: within a week two papers had already cited them and a dozen people had reached out to express their excitement about the models. We have a paper on it under review, and are leveraging the suite to do more Interpretability research. Currently the bulk of this work is oriented towards exploring the causes of memorization, but we also have threads about understanding how models learn social biases from data and how pretraining frequencies influence model knowledge.
We’ve also seen a surge of interest in work on Eliciting Latent Knowledge (ELK). Early in 2022 Igor Ostrovsky, Nostalgebraist, and Stella developed the “Tuned Lens,” a variation on Nostalgebraist’s Logit Lens. Unfortunately due to a combination of Igor starting a company and others being busy it languished for a bit until Nora Belrose picked it up again. Originally tasked with carrying the original idea across the finish line, her work has blossomed into a collection of research projects working on problems such as extracting interpretable basis for LLMs and detecting “deceptive-like” behavior.
Together, the “interpreting across time” and “eliciting-latent-knowledge” projects have prompted a flurry of activity in interpretability research, with nearly a dozen people actively working on papers on the subject at time of writing. The original channel quickly became overcrowded, so a new section of the discord server was set up with more channels and better organization.
Alignment Research
Reading groups and alignment related discussions on EAI continued, but with many of our alignment researchers leaving to work on alignment at Conjecture and OpenAI, we were not in a good position to do alignment research outside of interpretability. With the revitalization of EAI, this started to change in the second half of 2022.
Some alignment related concerns that are particularly notable to some of our members are alignment failures related to embedded agency. For instance, in RL there is a classic diagram that is taught to everyone on day 1 that shows an agent interacting with an environment in a loop:
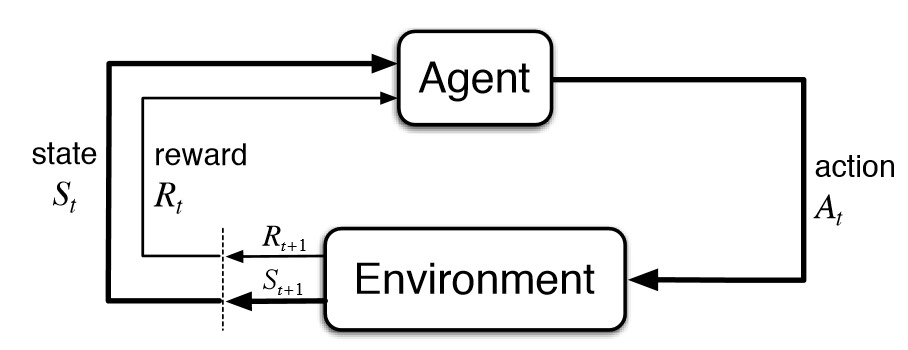
The canonical RL setup, but is it actually a good model of agents, especially once they get really smart and powerful?
Notably, it makes a few assumptions, like that reward comes from the environment, and that the agent is effectively separated from the environment. But this is not necessarily a good approximation of what would actually happen in a deployed system. The agent is part of the environment, and reward comes from somewhere inside that same environment. So speculative failure modes such as wireheading are back on the table. (See these posts for more of our thoughts on wireheading and its connection to embeddedness.)
In fact, the issue appears much broader than this, as in practice any mechanism for aligning AI systems, or correcting their behavior after they’ve been deployed is going to be part of the same environment as the agent, and prone to it’s interference.
This high level concern motivated the Alignment-Minetest project, which aims to modify the open source voxel engine Minetest so that we can look for wireheading and other undesirable incentives in agents and world models.
We are also interested in working on more projects in directions like inner alignment and ELK. While we've done some theoretical work in these directions (see: 1, 2, 3), we would be excited to do more theoretically-grounded empirical work in these directions using language models.
Going into 2023, we’re planning to spin up more alignment and interpretability projects and become significantly more involved with the broader alignment community.
Reflections
We’ve asked some of our members to give their thoughts on EAI over the past year, here’s some of their responses:
EleutherAI feels like a place where the only limits are just how big we can dream. The people I’ve met here are driven, scarily smart, and hypercompetent. More than anything, they’re united by an understanding of what defines good, lasting research that others should and do care about, and the ability to execute well on that understanding.
It feels like I fell backwards right into the best opportunity I’d ever get–I initially got the chance to be involved in Eleuther by pretty much being in just the right place at just the right time. People have been so welcoming and willing to share knowledge and research with me as long as I’m willing to learn, and I have indeed learned a ton in these past months. It’s been almost impossible to avoid absorbing the same enthusiasm I see here every day. I can’t wait to see what the future holds for EleutherAI, and can’t wait to keep repeatedly making the impossible happen.
-Hailey Schoelkopf
"Working at Eleuther AI on CARP genuinely gave me an experience in FOSS project management that I thought would be near impossible to achieve elsewhere. Being able to coordinate projects at scales that are unfathomable for most independent researchers let alone PhD students has opened my eyes to the kinds of projects that are achievable by randos on discord.
Came for the geese, stayed for the amazing collaborators." -CARP team
"I joined the EleutherAI discord server on my search for an open-sourced Github copilot, but what I found was much more than that!
EAI introduced me to the realm of transformers and the beautiful applications therein. From using TF-IDF and wordnets to being involved in state-of-the-art research, It has been a wild ride for me. And am lucky to have been guided by amazing folks along the way :) Can't wait to see what next year has in store for us!"
-Orz
"As far as I can tell, EAI's primary virtue is to be wrong in interesting and useful ways, and to do so consistently. This virtue is also my best guess as to the simple algorithmic core of alignment research."
-Quintin Pope
"Sure, EAI is the best 'great filter' for AI research. A place where someone like me (a novice) can directly interact with AI experts, where new ideas are born in casual chats on a Tuesday night and papers made in a discord channels are published in big conferences. It is all that and more. But for most us, it is also a home. A place where creativity, critical thought, experimentation, along with weird memes and endless debates, is just another day in the week. A safe heaven."
-Gabriel Syme
"EleutherAI doesn't have it all, but it has a lot. It has AI alignment discussion, it has AI capabilities discussion, it has memes, it has community, it even has geese. So many of my favorite things. I've made several real friends on the server. Here's to making a few more in the next year."
-TurnTrout
"I think Eleuther is really important because it’s by far the most transparent organization working on AI interpretability and alignment today. In my view, too many alignment-minded folks tend to think that open source models and open publishing of results are bad for the world, either because they accelerate AGI timelines or because they increase the risk that AI advances could fall into “the wrong hands.” While I understand this view, I disagree with it pretty strongly, so I’m glad to see that Eleuther— which has been pro-openness from the very beginning— has shifted toward interpretability work recently. I first got involved with Eleuther after a friend told me about some of the research that was being done in the interpreting-across-time channel, and since then I’ve done a lot of work with the help of Eleuther compute and volunteers which I definitely couldn’t have done otherwise."
-Nora Belrose
"One of my disciplines that I'd picked up over the years was high-performance computing and networking, and that's how I segued into working primarily with machine learning. I first encountered EleutherAI's work when looking for alternatives to AI storytellers, and loaded GPT-Neo 2.7B on a NVidia Jetson AGX. One thing lead to another when I got involved with the Anlatan crew and their first product, NovelAI. Their product utilized EleutherAI models with custom inference code, and I got involved with the backend programming there. I was brought in to help with CoreWeave's InfiniBand infrastructure for EleutherAI's GPT-NeoX 20B training project. I was happy to help, as I am a big believer in open models. This further expanded into architecting and building the goose.ai scalable inference infrastructure for an Anlatan-CoreWeave joint venture. By working with EleutherAI on advancing the research in large models, it has lead to a very interesting career shift into machine learning infrastructure leveraging my HPC knowledge and systems programming. EleutherAI is a collection of some of the sharpest and nerdiest folks that I have the honor of meeting, knowing, and working with -- and I look forward to what the coming year will bring us."
-Wes Brown
Extra Memes